System Design Question 12- E-Commerce Part 1 — Product Discovery: Catalog, Search & Recommendations
Designing a scalable product discovery system powering millions of users to browse, search, and discover products efficiently.

Designing an E-commerce platform is fundamentally about solving three independent but interconnected problems:
Product Discovery — How users find products
Shopping & Checkout — How users buy products
Fulfillment & Feedback — How products reach users and build trust
Because the system is massive, we are splitting it into three focused parts:
Part 1 (this article): Product Discovery — Catalog, Search, Recommendations
Part 2: Shopping & Checkout — Cart, Order, Inventory, Payments
Part 3: Fulfillment & Feedback — Shipping, Delivery, Reviews
👉 This separation allows us to design each system deeply while keeping responsibilities clean and scalable.
Also, each service here is essentially a standalone system design interview problem. I want to walk you through how to build the entire system incrementally—step by step across all services, not just one. However, Substack doesn’t support presenting content at that depth and structure. So here is the raw article how I planned -
RAW Designing an E-commerce platform LINK
Could you suggest a better platform where I can share this? I’m open to better options. The content is quite extensive, so I want a solution that handles scale and readability well.
Example I have four diagrams only for Catalog Service — Owning Product Truth -
Step 1/4: Entry points — How data enters the Catalog
Step 2/4: Add validation pipeline — Data goes through 4 stages before storage
Step 3/4: Add MongoDB + Redis — Storage with cache-aside pattern
Step 4/4: Add Kafka + downstream consumers — Complete event publishing
Below Design questions are previously covered topics in this blog-
System Design of Airbnb Part1 - User, Listings, Search & Availability
System Design of Airbnb Part2 - Booking & Reservations, Payment, & Reviews & Ratings
System Design of Airbnb Part3 - Messaging, Notifications, Trust & Safety, and Customer Support
System Design of Airbnb User QnA post articles - Prevent Double Booking
System Design of Twitter - Most in depth article you could find
1. Understand the Problem as a User
We aim to design the Product Discovery system of an E-commerce platform, enabling users to efficiently explore, search, and evaluate products before purchase.
Users interact with the system in three primary ways:
Catalog Browsing — navigating categories (e.g., Electronics, Fashion), exploring listings, and viewing product details (images, descriptions, price).
Search — expressing intent via queries (e.g., “iPhone 15”), with support for filtering (price, brand, rating, availability) and sorting (relevance, price, popularity). This is typically the dominant entry point.
Recommendations — discovering products through signals like “Recommended for you”, “Similar items”, driven by user behavior, product similarity, and trends.
The system also displays real-time product signals—approximate price, availability, and ratings—where slight staleness is acceptable. In parallel, it captures user interactions (searches, clicks, impressions) to continuously improve ranking and personalization.
👉 The goal is to deliver a low-latency, highly relevant, and scalable discovery experience for millions of concurrent users.
Loading...
Loading...
2. Requirement Gathering
2.1 Functional Requirements (FR)
The system must support multiple capabilities, each aligned with a specific stage of product discovery.
Catalog Management
Sellers should be able to create and update products, including metadata such as title, description, category, images, and attributes (e.g., size, color, brand). The system should support hierarchical categorization and flexible schemas to accommodate diverse product types.
Search System
Users should be able to perform full-text searches over product data with support for:
filtering (price range, category, brand, rating, availability),
sorting (relevance, price, popularity),
and fast retrieval of relevant results.
Search should also handle real-world complexities such as partial matches, synonyms, and typo tolerance.
Recommendation System
The platform should provide personalized and contextual recommendations, including:
user-based recommendations (based on history and preferences),
product-based recommendations (similar items),
and global signals (trending/popular products).
These recommendations should be dynamically updated based on user behavior and system-wide trends.
Product Detail View
Users should be able to view detailed product information, including:
product metadata,
approximate price,
rating summaries,
and availability snapshot.
This view acts as a decision point before checkout.
Inventory Visibility (Read-Only)
The system should display product availability (e.g., in stock/out of stock). This is a read-only view and does not involve reservation or locking, which will be handled in Part 2.
Pricing Visibility (Read-Only)
The system should display product prices, including basic discounts if applicable. Final pricing (taxes, coupons, shipping) is calculated during checkout.
Analytics & Tracking
The system must capture user interactions such as searches, clicks, impressions, and page views. These events feed into analytics pipelines and recommendation systems.
2.2 Non-Functional Requirements (NFR)
Scalability
The system should handle tens of millions of daily users, with high query-per-second (QPS) load on search and product views.
Low Latency
Search responses should typically be under ~200 ms
Product detail pages should load within ~100 ms (with caching)
High Availability
Product discovery should remain operational even if downstream systems (e.g., checkout) are partially degraded.
Eventual Consistency
The system can tolerate slight delays in:
search indexing,
inventory updates,
pricing updates.
Strict consistency is not required in discovery flows.
Relevance & Ranking Quality
Search and recommendation results must be highly relevant, as they directly impact user engagement and conversion.
Observability
The system should track:
search latency,
click-through rates,
conversion funnels,
and system health metrics.
2.3 Out of Scope
To keep the scope focused on discovery, the following are excluded and will be covered in later parts:
Order placement
Payment processing
Inventory reservation and locking
Shipping and delivery workflows
Returns and refunds
👉 These belong to Part 2 (Checkout) and Part 3 (Fulfillment).
3. BOE Calculations / Capacity Estimations
Assumptions:
Total users ≈ 200M → DAU ≈ 25% → 50M users/day
1 day ≈ 100K seconds (simplified from 86.4K)
Peak ≈ 3× average (instead of exact hourly distribution)
Search Traffic
Searches/day ≈ 50M × 5 = 250M
Avg QPS ≈ 250M / 100K = 2.5K (rounded division)
Peak QPS ≈ 2.5K × 3 = ~7–8K (approx multiplier)
Product Page Views
Views/day ≈ 50M × 10 = 500M
Avg QPS ≈ 500M / 100K = 5K (simplified seconds)
Peak QPS ≈ 5K × 3 = ~15K (approx peak factor)
Recommendations
Same as product views → 5K avg, ~15K peak QPS (reuse assumption)
Inventory Reads (Read-only)
Same as product views → 5K avg, ~15K peak QPS (1 read per view assumed)
Analytics Events
Events/day ≈ 50M × 10 = 500M
Avg QPS ≈ 500M / 100K = 5K (rounded math)
Peak QPS ≈ 5K × 3 = ~15K (same multiplier)
Catalog Size
100M products × 2KB ≈ 200GB (uniform size assumption)
Search Index
≈ 2.5× catalog → ~500GB (typical inverted index overhead)
Cache Impact
Backend load ≈ 15K × 15% ≈ ~2K QPS (assuming 85% cache hit)
Key Takeaways
Read-heavy → caching is mandatory
Search (~7–8K QPS) is core bottleneck
Cache reduces backend load → ~15K → ~2K QPS
4. Approach “Think-Out-Loud” (High-Level Design)
Before drawing service boundaries, it is important to understand the nature of Product Discovery. Unlike checkout or payments, this system is overwhelmingly read-heavy, latency-sensitive, and driven by ranking and retrieval problems, not transactional correctness. Users are not modifying critical state here—they are exploring, searching, and evaluating. That allows us to make a very important design decision early: we can trade strong consistency for performance and scalability.
At a high level, Product Discovery is a system that must efficiently answer three types of queries:
“Show me products matching this intent” (Search)
“Show me products I might like” (Recommendations)
“Show me everything about this product” (Product Detail)
Each of these queries has very different access patterns and computational requirements. That is the primary reason we cannot treat this as a single CRUD system over a product table.
4.1 Why Not a Monolith? Why Microservices Here?
If we were building a small-scale e-commerce platform, a modular monolith backed by a relational database would be a perfectly reasonable starting point. However, at scale, Product Discovery becomes a system of specialized read workloads:
Catalog requires flexible schema handling and frequent updates from sellers
Search requires full-text indexing, filtering, and ranking
Recommendations require behavioral data processing and model-driven outputs
Product detail pages require aggregation from multiple domains
Trying to handle all of this in a single service leads to two major problems. First, scaling becomes inefficient—a spike in search traffic forces scaling of unrelated components like catalog ingestion. Second, technology choices become constrained—you cannot use a search-optimized engine if everything is tightly coupled to a relational store.
That said, adopting microservices is not free. It introduces:
network overhead,
operational complexity,
data duplication,
eventual consistency issues.
So the justification is not “microservices are modern,” but rather:
The workload diversity and scaling characteristics in Product Discovery justify service separation.
4.2 Service Decomposition — Driven by Responsibilities
Instead of splitting services arbitrarily, we decompose the system based on clear ownership boundaries and query patterns.
The system naturally breaks into the following components:
Catalog Service (source of truth for product data)
Search Service (retrieval and ranking engine)
Recommendation Service (behavior-driven suggestions)
Product Detail Service (aggregation layer)
Inventory View Service (read-optimized availability snapshot)
Pricing View Service (display pricing)
Analytics/Event Service (behavior capture pipeline)
Each of these exists because it solves a different class of problem, not just to “have more services.”
How to Read the Architecture Diagrams
For every service, we build the architecture incrementally — starting with just the entry point, then adding one layer at a time (processing pipeline → storage → caching → event publishing). The final diagram in each sequence is the complete picture.
Follow the numbered arrows (1, 2, 3...) to trace any request end-to-end.
It includes holistic architecture diagrams at the beginning, followed by detailed per-service diagrams in the incremental build section. A written deep dive is provided at the end.
HOLISTIC ARCHITECTURE
Catalog Service — Owning Product Truth
The Catalog Service is responsible for managing the lifecycle of product data—creation, updates, attributes, categorization, and seller associations. It acts as the single source of truth for product metadata.
A natural question arises: why not let the search system directly store and serve product data?
Because search indexes are derived structures, optimized for retrieval—not correctness. They are not designed to handle complex workflows like moderation, schema evolution, or seller updates. By separating catalog from search, we ensure that:
correctness is preserved in one place,
search remains optimized for retrieval.
The tradeoff here is data duplication, since product data is also stored in search indexes. This introduces eventual consistency, but that is acceptable in discovery, where a few seconds of delay is tolerable.
Search Service — The Core of Discovery
Search is arguably the most critical component of Product Discovery. Users often directly express intent (“iPhone 15”, “running shoes”), and the system must respond with relevant, filtered, and ranked results within milliseconds.
A relational database is not sufficient here because search involves:
full-text queries,
tokenization,
stemming,
faceted filtering,
ranking algorithms.
This is why we introduce a dedicated search engine such as Elasticsearch or OpenSearch.
The key design decision is denormalization—instead of querying multiple services during search, we store a precomputed representation of products in the search index. This enables fast retrieval but introduces duplication and synchronization complexity.
The tradeoff is clear:
we sacrifice strict consistency,
in exchange for extremely fast and scalable search.
Given that discovery is latency-sensitive and read-heavy, this is a worthwhile trade.
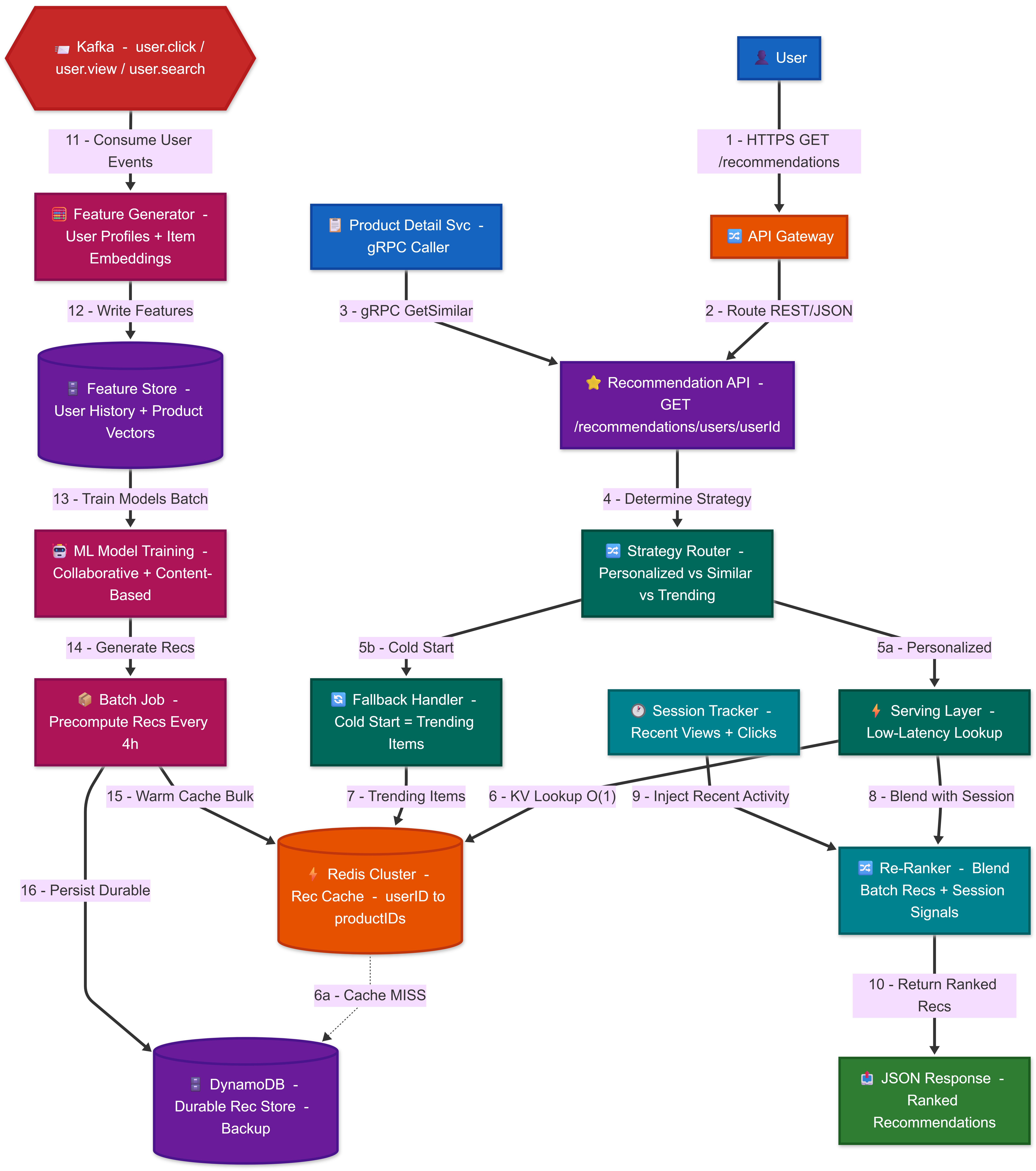
Recommendation Service — Solving a Different Problem
While search handles explicit intent, recommendations handle implicit intent. The system predicts what the user might want based on behavior such as:
previous views,
clicks,
purchases,
trends.
This requires a completely different pipeline involving:
event collection,
offline/online processing,
precomputed results,
low-latency serving.
Trying to merge this into the Search Service would blur responsibilities and slow down both systems. Instead, we isolate it into a separate service optimized for:
batch computation,
caching,
experimentation.
The tradeoff is additional system complexity, but the benefit is independent evolution and better personalization quality.
Product Detail Service — Controlled Aggregation
When a user opens a product page, they expect a fully composed response—not fragmented data coming from multiple endpoints. If the frontend were to call Catalog, Pricing, Inventory, and Recommendation services separately, it would result in:
higher latency,
increased network overhead,
duplication of orchestration logic.
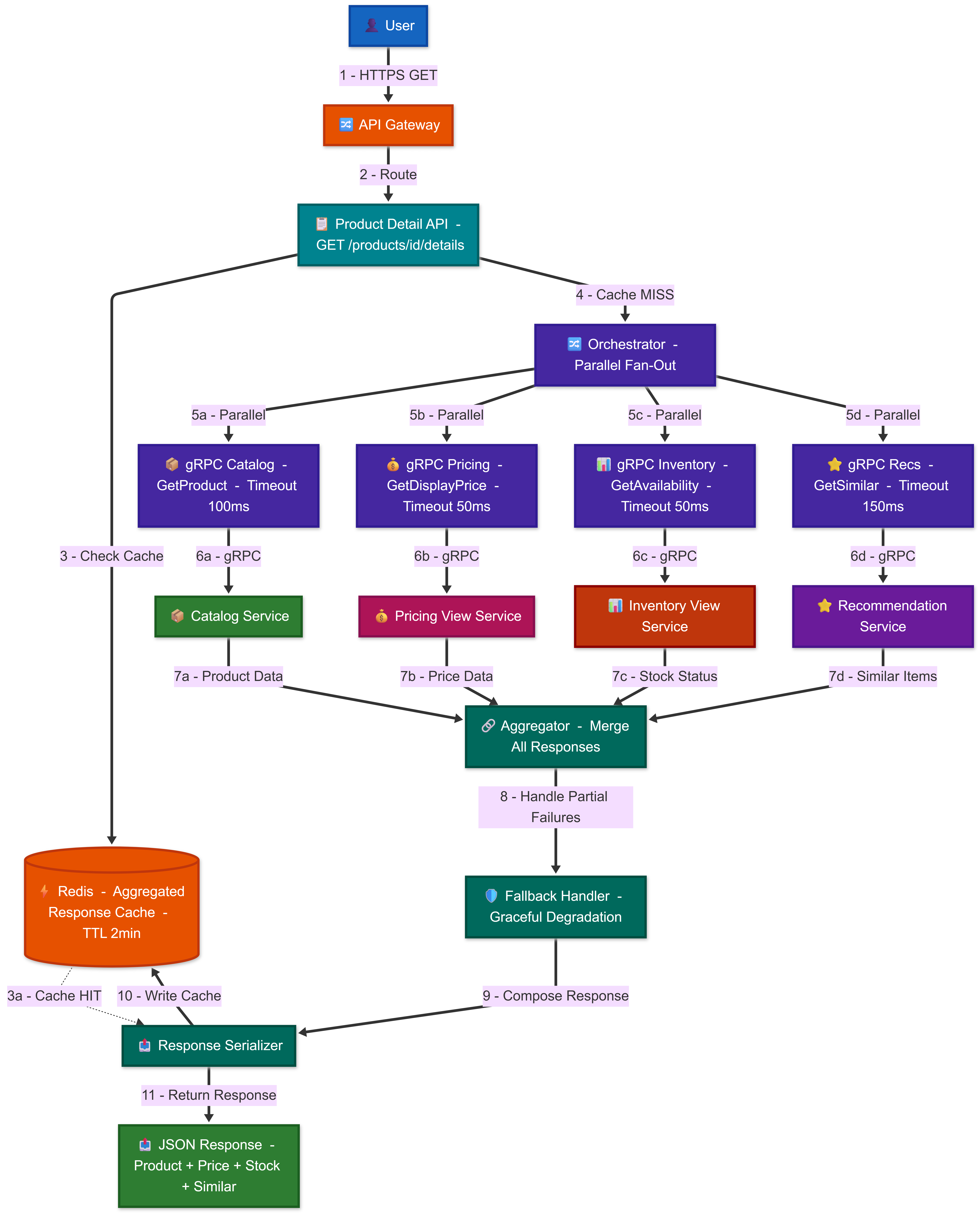
To solve this, we introduce a Product Detail Service that acts as a read aggregation layer. It fetches and combines data from multiple sources into a single response.
This introduces a new challenge—fan-out latency and dependency management. If one downstream service is slow, the entire response can be affected. To mitigate this, we rely on:
caching,
timeouts,
partial fallbacks.
This service does not own data; it composes it.
Add Aggregator + Fallback + Response — Complete
Inventory and Pricing — Read Projections, Not Ownership
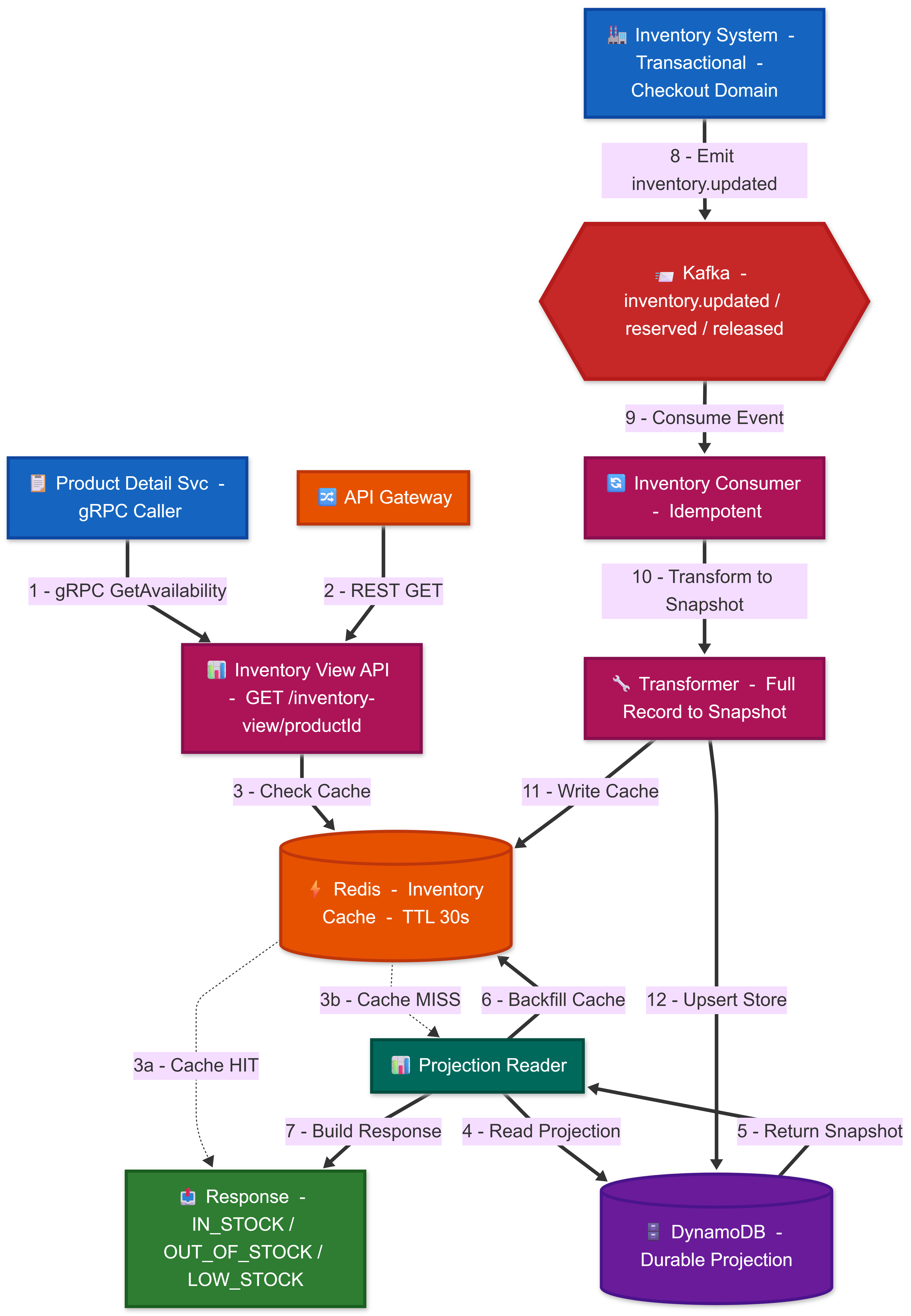
Inventory and pricing are critical domains, but in Product Discovery, we only need read-optimized views, not full transactional logic.
If discovery directly queries live inventory systems, it risks coupling user-facing traffic with critical transactional workloads. Instead, we expose:
an inventory snapshot (in stock / out of stock),
a display price view (approximate pricing).
These are derived, eventually consistent projections.
The tradeoff is possible staleness, but the benefit is decoupling discovery from transactional systems, which improves reliability and scalability.
INVENTORY VIEW SERVICE — Incremental Build
Add Kafka sync pipeline — Complete with event-driven updates
7. PRICING VIEW SERVICE — Incremental Build
Add Kafka invalidation — Complete with event-driven cache bust
Analytics/Event Service — Decoupling Behavior Capture
User interactions generate massive amounts of data:
searches,
clicks,
impressions.
Capturing this synchronously in core services would degrade performance. Instead, we adopt an event-driven approach, where events are asynchronously pushed into a streaming system (like Kafka).
This allows:
decoupled processing,
scalable ingestion,
feeding downstream systems like recommendations and analytics.
The tradeoff is delayed processing and operational overhead, but it ensures that user-facing APIs remain fast and unaffected.
ANALYTICS/EVENT SERVICE — Incremental Build
Add Grafana + Alerts — Complete observability loop
4.3 Polyglot Persistence — Why Multiple Databases?
A common simplification is to use a single database for all services. While this reduces operational complexity, it fails to optimize for different workloads:
Catalog → flexible schema storage
Search → full-text indexing
Recommendations → key-value access
Inventory → ultra-fast lookups
Analytics → append-heavy streams
No single database excels at all of these.
So we adopt polyglot persistence, choosing the right database for each workload.
This introduces:
operational overhead,
data duplication,
consistency challenges.
But it enables each component to operate at optimal efficiency, which is critical at scale.
5. Databases & Rationale (Service-Aligned)
Catalog Service → MongoDB / DynamoDB (Document Store)
Flexible schema for heterogeneous product attributes (electronics vs fashion).
Tradeoff: weaker relational constraints, but avoids schema explosion.
Search Service → Elasticsearch / OpenSearch
Optimized for full-text search, filtering, ranking, and faceting.
Tradeoff: denormalized data + eventual consistency from Catalog.
Recommendation Service → Redis (+ NoSQL backing store)
Low-latency serving of precomputed recommendations (user→products, product→similar).
Tradeoff: memory-heavy; durability handled outside Redis.
Inventory View Service → Redis / DynamoDB (Key-Value)
Fast lookup: productId → availability snapshot.
Tradeoff: eventual consistency; authoritative checks happen in checkout.
Pricing View Service → Relational DB + Cache
Structured pricing rules with cached display price for fast reads.
Tradeoff: slight mismatch possible vs final checkout pricing.
Analytics/Event Service → Kafka (+ Data Warehouse)
High-throughput event ingestion with downstream processing.
Tradeoff: async pipelines introduce delay and operational overhead.
6. APIs
Catalog Service
POST /catalog/products → Create product (seller/admin flow)
PUT /catalog/products/{id} → Update product metadata
GET /catalog/products/{id} → Fetch canonical product data
Search Service
GET /search?q=&filters=&sort= → Return ranked, filtered product list (denormalized fields)
Product Detail Service
GET /products/{id}/details → Aggregated response (catalog + price + inventory + recommendations)
Recommendation Service
GET /recommendations/users/{userId} → Personalized recommendations
GET /recommendations/products/{productId} → Similar/related products
Inventory View Service
GET /inventory-view/{productId} → Availability snapshot (IN_STOCK / OUT_OF_STOCK)
Pricing View Service
GET /pricing-view/{productId} → Display price + discount info
Analytics/Event Service
POST /events → Capture user events (search, click, view, impression)