

Part 1: System Design of Zoom/Teams-Like Platform — Real-Time Voice & Video, Recording & Playback, Notifications & Reminders, Logging & Monitoring
Completing the real-time core infrastructure of an enterprise-scale video conferencing system, focusing on ultra-low-latency audio/video, robust recording, timely notifications, and observability.

Designing a scalable, enterprise-grade video conferencing platform involves multiple complex services, but four foundational pillars typically drive the core user experience and system stability:
Real-Time Voice & Video Streaming – low-latency audio/video delivery for 1:1 calls or large group meetings.
Recording & Playback – capturing live sessions and serving them on-demand with reliability and high fidelity.
Notifications & Reminders – prompting participants about upcoming meetings, new recordings, or important system updates.
Logging & Monitoring – ensuring real-time visibility into service performance, user QoS, and system health.
We will cover other critical modules (such as Chat, Meeting Management, Screen Sharing, Security, etc.) in subsequent parts. This Part 1 lays out the in-depth design considerations for these four pillars, referencing the scale of modern platforms like Zoom and Microsoft Teams.
1. Understand Question as User
We aim to build a globally accessible video conferencing system that can accommodate tens of millions of daily users, handle thousands of concurrent participants in large webinars, record sessions reliably, send timely notifications, and continuously collect logs/metrics for operational intelligence.
Our key goals for Part 1 are:
Real-Time Voice & Video Streaming
Sub-300ms latency for live interaction.
Adaptive bitrate (ABR) to handle varying network conditions.
Seamless handling of NAT/firewalls via STUN/TURN servers.
Recording & Playback
On-demand or automatic recording of video sessions.
Storage in a fault-tolerant environment.
Playback services that handle high concurrency.
Notifications & Reminders
Notify users of upcoming meetings.
Push updates (email, mobile push) regarding new recordings or urgent announcements.
Ensure notifications are timely and not duplicated.
Logging & Monitoring
Real-time dashboards for usage metrics (active participants, bandwidth consumption).
Tracing and logs for debugging video quality issues or server errors.
Alerts on threshold breaches (high packet loss, CPU overload).
We want to deliver these features at large scale with strong reliability, security, and performance.
2. Requirement Gathering
2.1 Functional Requirements (FR)
2.1.1 Real-Time Voice & Video Streaming
Low Latency: Maintain interactive audio/video with minimal delay (ideally under 300ms round-trip).
Scalable Infrastructure: Support 1:1 calls, small group meetings, and large webinars with hundreds or thousands of participants.
Adaptive Bitrate: Automatically adjust resolution/bitrate based on network conditions.
Device and Network Agnosticism: Handle a wide range of devices (mobile, desktop, browser) and diverse network conditions.
2.1.2 Recording & Playback
On-Demand & Scheduled Recording: Allow hosts to trigger recording manually or schedule automatic recording.
Multiple Layouts: Capture either a single mixed feed or separate participant streams for post-processing.
Secure Storage: Store large media files in a fault-tolerant environment (object storage).
Playback Service: Provide accessible links for on-demand streaming, possibly with multiple transcoded formats.
2.1.3 Notifications & Reminders
Meeting Reminders: Alert participants via email, push, or SMS about upcoming meetings.
Recording Availability: Notify host/participants when a session’s recording is ready.
System Alerts: Inform users about system-wide issues or maintenance windows.
Configurable Preferences: Let users enable/disable or customize notification channels.
2.1.4 Logging & Monitoring
Centralized Log Collection: Collect logs from all microservices (signaling, media servers, recording, etc.).
Real-Time Metrics: Track system load, concurrent streams, audio/video quality metrics (packet loss, jitter), and resource usage.
Alerting & Visualization: Provide dashboards and triggers for anomalies (high error rates, server CPU spikes).
Long-Term Analysis: Archive logs for auditing or usage trends over time.
2.2 Non-Functional Requirements (NFR)
Scalability: Handle millions of daily users globally, with thousands of concurrent active streams.
High Availability & Reliability: Minimal downtime; replicate critical components across regions.
Security & Privacy: Ensure encryption in transit (TLS/SRTP), user authentication, data protection (recordings, logs).
Performance: Real-time streaming must not exceed recommended latency thresholds.
Observability: Rich metrics, logs, and alerting to quickly diagnose issues.
Global Reach: Deploy services or media edges across continents to reduce round-trip time.
2.3 Out of Scope
Chat or text collaboration features (to be addressed in a later part).
Detailed meeting management (scheduling, breakout rooms, advanced host controls).
Extensive screen-sharing or whiteboard collaboration.
Comprehensive enterprise billing and licensing models.
3. BOE Calculations / Capacity Estimations
3.1 Real-Time Voice & Video
Concurrent Participants: Assume 10 million concurrent participants globally at peak.
Bandwidth: A typical 720p video stream ~1–2 Mbps, so total throughput can be in the tens of Tbps if all participants are streaming video.
Transcoding or SFU: Depending on architecture, an SFU (Selective Forwarding Unit) largely forwards streams with minimal transcoding overhead. For large events, MCUs (Multipoint Conferencing Units) or broadcast servers can be used, but they require more CPU.
3.2 Recording & Playback
Recording Rate: If 5% of meetings are recorded, and we have 10 million daily meetings, that’s ~500k recorded sessions/day.
Average Recording Size: ~1–2 GB/hour for a typical multi-participant HD session. Leads to ~500 TB–1 PB of new data/day at scale.
Playback Concurrency: Thousands of users might watch recorded sessions simultaneously, requiring a CDN or streaming-optimized approach.
3.3 Notifications & Reminders
Meeting Reminders: If half of the 10 million daily users opt-in to reminders, that’s up to 5 million notifications/day.
Recording Notifications: If each recorded meeting notifies an average of 5 participants, that’s another 2.5 million notifications/day. Must handle spikes during peak hours.
3.4 Logging & Monitoring
Log Volume: Each participant session might generate dozens of events per minute (join/leave, QoS stats, error logs). Over tens of millions of sessions, logs can easily exceed billions of entries/day.
Storage & Indexing: Potentially tens of TBs of log data daily, requiring a distributed log processing pipeline (e.g., Kafka + Elasticsearch/S3).
4. Approach “Think-Out-Loud” (High-Level Design)
4.1 Architecture Overview
We propose a microservices-based approach, isolating each critical function—Real-Time Voice & Video, Recording, Notifications, and Logging—into dedicated modules that can scale independently and communicate over well-defined APIs/events.
Signaling Service (not the full focus of Part 1, but necessary context)
Manages user presence, call set-up, and media negotiation (WebRTC, ICE).
Media Server Cluster (Real-Time Streaming)
SFU-based approach for large group calls, forwarding streams with minimal overhead.
Possibly an MCU or transcoding layer for special use cases (webinars, streaming to external CDNs).
Recording Service
Hooks into media servers or special “recorder nodes” to capture sessions.
Stores files in object storage, triggers post-processing/transcoding if needed.
Playback Service
Serves recorded files on-demand through a content delivery network (CDN).
Provides user-friendly links to watch or download.
Notification Service
Schedules and sends meeting reminders and real-time notifications (email, push, SMS).
Integrates with the Recording Service to send “recording-available” alerts.
Logging & Monitoring Service
Aggregates logs from all components (signaling, media, recording, notifications).
Offers real-time dashboards, alerting, and long-term storage of logs/metrics.
Communication is primarily event-driven (via a queue or pub/sub system like Kafka) plus some synchronous REST/gRPC calls for user-level interactions (e.g., “start recording” request).
4.2 Data Consistency vs. Real-Time Updates
Media Streaming: Must be strictly real-time with minimal buffering (WebRTC, SRTP).
Recording: Write operations to object storage can be asynchronous, but final file references must be strongly consistent.
Notifications: Eventually consistent is often acceptable, but triggers (like “meeting starts in 10 min”) need accurate scheduling.
Logging: Large volumes with near real-time ingestion but typically eventual consistency for analytics dashboards.
4.3 Security & Privacy Considerations
Media Encryption: SRTP/TLS for in-transit protection.
Recording Consent: Regulatory compliance requires participants’ consent.
Data Protection: Encrypt recordings at rest, handle RBAC for playback.
Log Sanitization: Avoid sensitive info (PII) in logs or mask it appropriately.
5. Databases & Rationale
Real-Time Voice & Video
Minimal direct DB usage: ephemeral session data often kept in memory or distributed caches.
Redis or In-Memory for session state (who is connected, region allocations).
Recording & Playback
Metadata: Use a NoSQL store (MongoDB) for storing recording references, meeting ID, status, and ownership.
Media Files: Large object storage (S3 or equivalent) for raw/processed recordings.
Notifications & Reminders
Scheduling: A relational DB to store user preferences, upcoming meeting times.
Event Queue: Kafka for asynchronous dispatch of notification jobs.
Logging & Monitoring
Time-Series / Search DB: Elasticsearch, Splunk, or a managed cloud logging solution for indexing logs.
Metrics DB: Prometheus or similar for numeric metrics (CPU, memory, packet loss).
Long-Term Storage: Offload logs to a cheaper store (e.g., S3, Glacier) after retention period.
6. APIs
Below are representative endpoints focusing on the four pillars.
6.1 Real-Time Voice & Video
(Internal) POST /media/allocate
Payload: { meetingId, region }
Response: { mediaServerId, allocatedResources }
Description: Orchestrates resource allocation on an SFU/MCU node for new participants.
(Internal) POST /media/updateBitrate
Payload: { userId, meetingId, newBitrate }
Response: 200 OK
Description: Notification to the client that the system has adjusted the stream quality.
6.2 Recording & Playback
POST /recording/start
Payload: { meetingId, layoutMode }
Response: { recordingId, status: "STARTED" }
Description: Begins recording the session; triggers the Recording Service to latch onto media streams.
POST /recording/stop
Payload: { recordingId }
Response: { recordingId, status: "COMPLETED", fileLocation }
Description: Finalizes the recording and prepares it for storage.
GET /playback/{recordingId}
Response: Metadata + streaming endpoint or an HTTP 302 redirect to a CDN link.
Description: Provides access to the recorded file for on-demand playback.
6.3 Notifications & Reminders
POST /notifications/schedule
Payload: { meetingId, userId, notifyTime, channel: "email" | "push" | "sms" }
Response: { notificationId }
Description: Schedules a reminder for an upcoming event or post-event follow-up.
POST /notifications/send
Payload: { notificationId, content }
Response: 200 OK
Description: (Internal) Triggered by the scheduler or event bus to actually dispatch the notification.
6.4 Logging & Monitoring
POST /logs/bulk
Payload: [ { timestamp, serviceName, level, message }, … ]
Response: 200 OK
Description: Collects logs from different services and ingests them into a centralized store.
GET /metrics
Response: Summarized performance indicators (activeCalls, averageBitrate, errorsPerMin, etc.)
Description: Consumed by a monitoring tool (Prometheus or Datadog) for dashboards/alerts.
7 Deep Dive into Core Services
7.1 Real-Time Voice & Video (Signaling + SFU)
7.1.1 Responsibilities
7.1.1.1 Signaling for Call Setup
A critical responsibility of any real-time communication platform is establishing and maintaining the session between participants. Signaling involves the exchange of session descriptions (e.g., WebRTC Session Description Protocol, or SDP) and Interactive Connectivity Establishment (ICE) candidates. These are required to determine how media will flow between end-users, especially when participants are behind firewalls or Network Address Translators (NATs). Through this process, clients learn which IP addresses, ports, and transport protocols are viable for sending and receiving media streams.7.1.1.2 SFU for Forwarding or Mixing Participant Streams
An SFU (Selective Forwarding Unit) is typically used to receive media streams from each participant and forward them to other participants. One of the most notable advantages of SFUs is that each participant only encodes and sends a single stream, while the SFU multiplexes it to other participants. In contrast, an MCU (Multipoint Conferencing Unit) mixes streams into one composite feed but can demand higher server resources. In large group calls (e.g., a 100-person event), the SFU approach often performs better from a client perspective because each participant’s device does less encoding work.7.1.1.3 Adaptive Bitrate Control
Network conditions vary widely among participants—some might be on fiber connections, others on cellular networks. The system must continuously measure key metrics like packet loss, jitter, and round-trip time, then adjust video bitrate and resolution on the fly. This ensures that a participant with lower bandwidth still receives a smooth, if lower-quality, experience, while a participant with ample bandwidth gets a high-definition stream.
7.1.2 Core Components
7.1.2.1 Signaling Layer (WebSockets or WebRTC DataChannels for Negotiation)
The signaling layer is typically exposed as a WebSocket endpoint (or other real-time channel). This allows clients to send their SDP offers, ICE candidates, and control messages such as “mute,” “turn off video,” or “switch camera” to the server. In a browser-based architecture, the WebRTC API handles local media streams and interacts with the signaling server for negotiation. For example, a participant’s browser gathers ICE candidates (local IP, STUN-derived IP, TURN servers) and sends them to the Signaling Service. The service, in turn, relays these to other participants (or the SFU) so they can establish a direct or relayed connection.7.1.2.2 SFU Cluster (Deployed Regionally for Minimal Latency)
To provide good quality for participants scattered around the globe, you might deploy multiple SFU instances in different regions—e.g., North America, Europe, Asia. When a user attempts to join a call, the platform determines which SFU region is closest or least loaded. Participants in Europe might connect to an SFU located in Frankfurt, while those in North America might connect to a U.S.-based SFU if the meeting is likewise hosted there. Internally, these SFUs might communicate or coordinate with each other if the call has participants spanning geographies.7.1.2.3 TURN Servers (Relay Media When Direct Peer Connections Fail)
A TURN (Traversal Using Relays around NAT) server becomes essential if direct peer-to-peer paths are blocked by strict NAT/firewalls. TURN relays the audio/video packets between endpoints and the SFU. Although TURN introduces an additional hop that can increase latency, it is indispensable in many corporate or restrictive network environments to ensure participants can still join calls. Large organizations, for instance, may have their own STUN/TURN infrastructure to manage traffic routing securely behind their firewalls.
7.1.3 Corner Cases
7.1.3.1 NAT/Firewall Complexity → Must Have Robust STUN/TURN Logic
Consider a scenario where a user in a strict corporate environment cannot receive inbound UDP traffic, forcing all traffic through TCP port 443. The system’s STUN approach might fail to gather a functional IP candidate, so the participant’s connection automatically falls back to TURN over TLS. To the user, this is seamless, but under the hood, the signaling service must quickly detect the user’s restrictive environment and direct them to the correct TURN server. Failure to do so might result in users being completely unable to see or hear each other.7.1.3.2 Large Events → Possibly Switch to MCU
Suppose your platform is hosting a virtual town hall for 5,000 attendees. An SFU forwarding every participant’s stream to all others is impractical in such large scenarios. Instead, you might rely on an MCU or a broadcast approach: The platform designates a few presenters who speak and share video, while other participants are in a view-only mode. In effect, the MCU mixes the presenters’ video feeds into one composite stream that is more bandwidth-efficient to distribute.7.1.3.3 Sudden Network Changes → ABR Must Promptly Adjust or Fallback to Audio-Only
Imagine a participant is commuting, initially on fast 5G, but unexpectedly moves into a tunnel where the signal degrades. The SFU (or the local client logic) detects increased packet loss and instructs the user’s device to step down from 720p to 360p. If conditions worsen still, it might disable video entirely so at least audio remains. This dynamic adaptation ensures continuity of communication, even under difficult network conditions.
7.2 Recording & Playback
7.2.1 Responsibilities
7.2.1.1 Start and Stop Capturing Video/Audio Feeds Based on Host Commands
Recording is typically governed by the host or an authorized user. The system should provide an API or in-meeting control to “Start Recording.” Once triggered, the platform begins capturing the real-time feeds—whether directly from the SFU, or via a dedicated mixing service (MCU). At the end of the meeting or when the host stops the recording, the system finalizes the file, ensuring no partial segments are left behind.7.2.1.2 Combine or Store Individual Participant Streams
There are generally two approaches to recording:7.2.1.2.1 Individual Tracks: The system records each participant’s audio/video stream separately. This approach allows post-processing flexibility, like re-mixing or focusing on active speakers. However, it consumes more storage and computational overhead.
7.2.1.2.2 Composited Track: An MCU (or specialized mixer) merges all participant feeds into a single video track. This is simpler to manage for playback but limits post-processing flexibility.
7.2.1.2.2.1 Upload Final Media Files to Object Storage, Track Metadata in DB
After a recording session is complete, a robust mechanism must push the raw or encoded media to a secure, durable storage solution (e.g., AWS S3, Google Cloud Storage, on-premises object stores). Alongside the media file, the system stores metadata—meeting ID, recording start/end time, file size, host ID—so that subsequent retrieval or playback is straightforward.
7.2.2 Core Components
7.2.2.1 Recording Engine
This can be an MCU-based solution (mixing streams on the fly) or an SFU “tap” that subscribes to participant streams for the sole purpose of creating a local recording. In many architectures, the SFU itself can forward a copy of each track to the Recording Engine, which then assembles them. For example, if a meeting has 5 participants, the Recording Engine might receive 5 inbound media streams and either write them as separate files or mix them into a single track.7.2.2.2 Storage Tier
Given the high volume of recordings in large organizations, object storage remains the go-to solution for storing large media files. It can handle massive daily ingestion without performance degradation. Replication policies ensure that even if one data center experiences issues, the recordings remain intact. Many organizations also incorporate CDN layers if recordings are accessed frequently from multiple global regions.7.2.2.3 Transcoding/Indexing (Optional)
Some platforms automatically transcode recordings into multiple formats—e.g., 480p, 720p, 1080p—so users on slower networks can stream them more smoothly post-meeting. Indexing might include generating subtitles or transcripts via speech-to-text algorithms. These transcripts can be stored alongside the recording metadata, allowing users to search for specific keywords within a recorded session.
7.2.3 Corner Cases
7.2.3.1 Partial Recordings if a Crash Occurs Mid-Meeting → Must Handle Graceful Recovery
Imagine the Recording Engine crashes or the SFU unexpectedly restarts. The system could lose in-progress video segments. A robust design might store partial chunks every few seconds. So if a crash occurs at the 20-minute mark of a 60-minute session, the first 20 minutes are already safely on disk. When the system recovers, it can attempt to resume or create a new file. The final combined recording would need to stitch these segments together, preserving continuity as much as possible.7.2.3.2 Privacy Concerns → Require User or Host Consent to Record
In many jurisdictions, explicitly notifying participants that recording is happening is legally required. The platform should display a clear banner or announcement—“Recording in progress”—and possibly allow participants to opt-out or leave the meeting if they disagree. Additionally, some enterprise-grade platforms enforce “host-only” recording privileges, ensuring no participant can record secretly.7.2.3.3 Storage Costs → Implement Retention Policies or User-Based Quotas
With thousands of hours of recorded content pouring in daily, storing everything forever is cost-prohibitive. Organizations often establish retention policies—e.g., auto-delete recordings after 90 days unless marked for archival. A user-based quota system can also let individuals see how much storage they have used, prompting them to clean up old recordings if needed. These strategies prevent runaway storage bills and keep data more organized.
7.3 Notifications & Reminders
7.3.1 Responsibilities
7.3.1.1 Proactively Alert Users About Upcoming Meetings
A robust notification system ensures participants don’t miss important meetings. For example, if a user schedules a meeting for 3 PM, the platform might send an email or push notification 15 minutes prior. This may be integrated with calendar systems (e.g., Outlook or Google Calendar) or function independently.7.3.1.2 In-Meeting Notifications (Recording Start, Connectivity Warnings)
Beyond pre-meeting reminders, real-time notifications within the session can enhance user awareness. For instance, if the host starts recording, a pop-up is instantly shown to all participants stating, “Recording has started.” Likewise, if the platform detects a user’s internet connection has deteriorated significantly, it could display “Your connection is unstable, consider switching off your video.”7.3.1.3 Post-Meeting Notifications (Recording Availability)
Once a session is recorded, participants (especially those who missed the meeting) may receive a link to watch or download the recorded session. This can be a direct email or a push notification in the user’s chat/collaboration interface—“Your meeting with ID #12345 has been recorded. Click here to play back.”
7.3.2 Core Components
7.3.2.1 Scheduler (Cron or Event-Based) That Checks for Upcoming Reminders
Many platforms maintain a schedule of future meetings in a relational database. A background job—running every minute—searches for meetings starting in 5, 10, or 15 minutes (depending on user preferences) and triggers notifications. Alternatively, an event-driven system might rely on message queues to handle scheduled tasks. When the meeting is created, the system enqueues a “send notification” event to be executed at the appropriate time.7.3.2.2 Push/Email Gateway Integrating with Apple’s APNs, Google FCM, or SMTP
To reach mobile and desktop apps, the system commonly uses push notification services. For iOS, Apple’s APNs is used; for Android, Google Firebase Cloud Messaging is used. Desktop or web apps can receive push messages via web push protocols or specialized in-app messaging. Email reminders, on the other hand, rely on SMTP servers or third-party providers (e.g., SendGrid, AWS SES) for reliable and scalable delivery.7.3.2.3 Preference Store for User Notification Settings (Opt-Out, Email Only, Etc.)
Not all users want frequent notifications. Some might prefer only email, some push notifications, or both. A preferences table typically stores (userId, notifyByEmail, notifyByPush, doNotDisturbTimes, etc.). When the notification microservice decides to send an alert, it checks these preferences to determine which channel(s) to use, or whether to skip the notification entirely if the user has opted out.
7.3.3 Corner Cases
7.3.3.1 Time Zone Mismatch → System Must Store All Times in UTC and Convert Locally
Imagine a user in New York schedules a meeting at 3 PM Eastern Time, while participants in London see it as 8 PM local time. If the system doesn’t store and process times in a consistent UTC format, participants might get notifications at the wrong local times. This can lead to confusion and missed sessions. Ensuring consistent time zone handling is crucial for a global user base.7.3.3.2 Notification Overload → Rate-Limiting or Bundling Notifications to Avoid Spam
For a busy user with back-to-back meetings, it’s easy to get hammered with multiple reminders in a short span. A well-designed system might bundle or group notifications—e.g., “You have 3 upcoming meetings in the next hour. Open your schedule for details.” This prevents frustration and fosters a cleaner user experience.7.3.3.3 Offline Users → Queue Notifications for Later Delivery (Push Tokens That Might Expire)
Mobile devices or browsers may lose connectivity. If a push token is expired, the notification platform must detect and handle it gracefully—attempting to re-acquire a valid token, or fallback to email or SMS. For example, if a user’s phone is off and misses the scheduled push at 2:45 PM, the platform might queue the notification and try again once the phone signals it’s online, or it might send an email if the user has that channel enabled.
8 D. Logging & Monitoring
8.1 Responsibilities
8.1.1 Collect Real-Time Logs from SFUs (Packet Loss, Bitrates) and Signaling Service (Join/Leave)
The real-time nature of video calls generates a wealth of operational data: which participant joined at what time, their network stats, how many times they reconnected, etc. Similarly, the SFU tracks each forward stream’s bitrate, packet loss rate, and CPU usage. This data is crucial for diagnosing call issues (“Why is the audio choppy?”) and for planning capacity expansions (“Do we need another SFU cluster in Asia?”).8.1.2 Surface Metrics in Dashboards for Operational Staff
Operations teams rely on live dashboards to gauge the health of the system. They might see the total number of ongoing calls, average CPU/memory usage across SFU clusters, or error rates in the Signaling Service. A quick glance can reveal anomalies such as a spike in packet loss for a specific region, hinting at potential ISP issues.8.1.3 Alert on Anomalies (e.g., High SFU CPU Usage, Excessive Reconnection Attempts)
Automated alerting systems are configured to trigger notifications to on-call engineers or operations staff. For instance, if CPU usage on an SFU climbs above 80% for more than 5 minutes, an alert is fired—giving teams a chance to add more nodes or reroute traffic before quality degrades. Similarly, an unusual surge in reconnection attempts might indicate a bug in the signaling process or an intermittent network outage.
8.2 Core Components
8.2.1 Log Aggregator (Fluentd, Logstash) Sending Logs to Elasticsearch or Similar
Logs from SFUs, Turn servers, and the Signaling Service can be voluminous. A Log Aggregator picks up these logs (usually from Docker containers, VMs, or systemd logs), formats them in a common schema (JSON often works well), and ships them off to a centralized storage/indexing system like Elasticsearch, Splunk, or OpenSearch. Engineers can then search historical logs—e.g., “Show me all errors from the SFU cluster in Frankfurt between 10 AM and 11 AM UTC.”8.2.2 Time-Series Database (Prometheus, InfluxDB) for Numeric Metrics
For metrics like active calls, packet loss percentages, CPU usage, or average bitrates, a time-series database is standard. Prometheus, for example, periodically scrapes endpoints (e.g., GET /metrics) exposed by services. This data is stored with timestamps, enabling the creation of graphs that depict how these metrics change over time. If the number of active calls jumps from 1,000 to 5,000 in 5 minutes, the system can detect it and trigger autoscaling or alerting.8.2.3 Alerting System (PagerDuty, OpsGenie) Integrated with Threshold-Based Triggers
Once you define thresholds—“SFU CPU usage > 80%” or “Packet loss rate > 5% for more than 30 seconds”—the monitoring platform can automatically raise an alert. These alerts can be integrated with on-call rotations in services like PagerDuty. In a real scenario, if an SFU region experiences a sudden load spike, the system might simultaneously push an alert to Slack, send an SMS to the on-call engineer, and also log the event for further analysis.
8.3 Corner Cases
8.3.1 Log Volume Spikes During Large Conferences or Global Events → Must Handle Ingestion Bursts
When a high-profile event takes place—like a worldwide product launch or an all-company meeting—tens of thousands of participants may join at once. SFUs will generate a surge in logs, from join/leave events to bandwidth reports. Without a scalable ingestion pipeline, the logging service could choke, leading to lost logs that hamper investigations. A well-architected solution might temporarily buffer logs in a message queue (Kafka) before streaming them to Elasticsearch, absorbing bursts more gracefully.8.3.2 Sensitive Data → Mask Personal Info in Logs to Ensure Compliance
Privacy laws require that logs containing personal data—names, phone numbers, email addresses—be handled with care. A simple slip can compromise user privacy if raw logs are searchable by engineering staff. Many platforms implement log sanitization that replaces personally identifiable data with placeholders or hashed tokens. For instance, a log entry for a user’s email might read "[email_obfuscated]".8.3.3 High Cardinality Metrics → Carefully Design Labels/Tags
In a time-series database, each unique combination of metric labels (e.g., meeting_id, region, participant_id) creates a new time series. If you label metrics with a unique participant ID for every single call, you might blow up the cardinality, overwhelming the database. Instead, metrics might be aggregated at the SFU or meeting level, limiting the number of unique label combinations. This approach keeps the monitoring infrastructure stable and cost-effective.
8. Bringing It All Together (Part 1)
By focusing on these four pillars:
Real-Time Voice & Video Streaming
Ensures a smooth, low-latency user experience across geographies and network types.
Scales via SFU clusters and adaptive bitrate to handle massive concurrency.
Recording & Playback
Captures the live interaction for future reference, compliance, and user convenience.
Relies on cloud object storage for durability and a playback service (possibly with CDN integration).
Notifications & Reminders
Keeps participants engaged and informed about upcoming sessions and newly available recordings.
Requires robust scheduling and handling of large notification spikes.
Logging & Monitoring
Gives operators and engineers the observability to maintain system health, respond to incidents, and plan capacity.
Collects crucial QoS metrics (latency, packet loss) for proactive improvements.
Each of these microservices or modules forms the backbone of a resilient video conferencing platform, delivering critical functionality at scale. While Part 1 establishes these fundamental services, future expansions will address Chat, Meeting Management, Screen Sharing, Security Enhancements, and advanced features that round out a full Zoom/Teams-like solution.
By adhering to best practices in architecture (regional SFU deployments, distributed logging), security (TLS/SRTP, secure storage for recordings), and observability (centralized logging, real-time metrics dashboards), we can confidently scale to millions of daily participants and thousands of concurrent meetings worldwide—ensuring a quality experience for every call.
End of Part 1
Bonus Read: Typical Meeting Flow (Focusing on Part 1 Components)
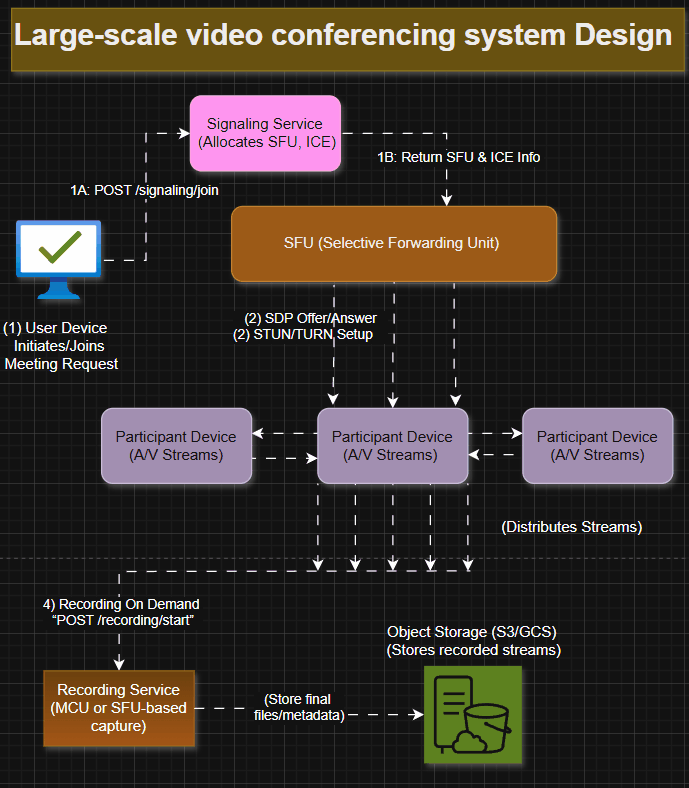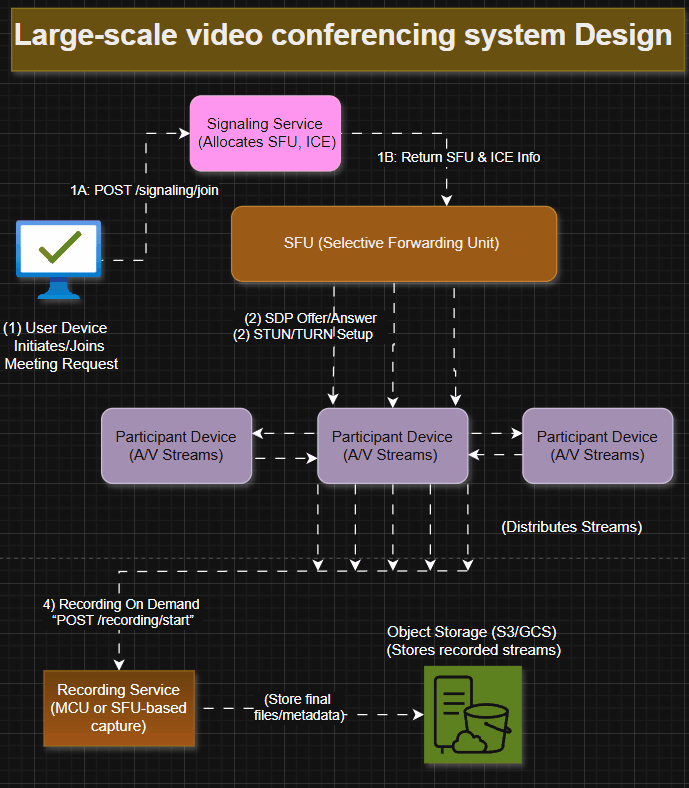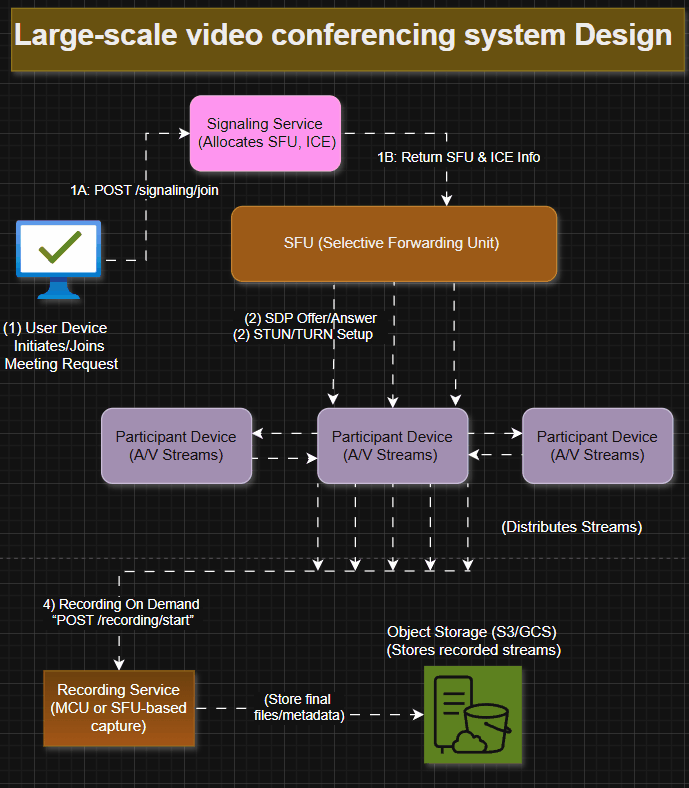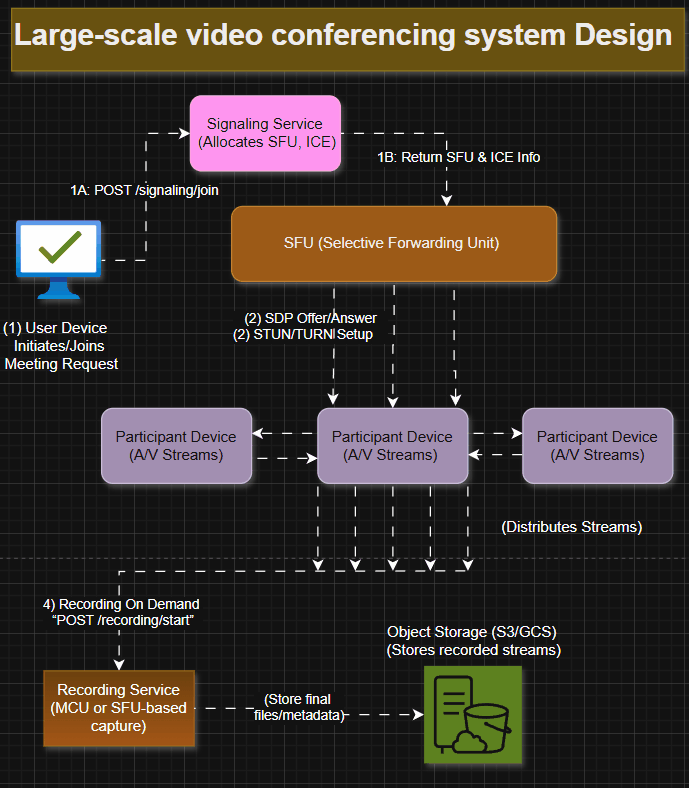
1. User Initiates/Joins Meeting
User Action
A participant (let’s call them Alice) opens her conferencing app (web-based or native) and selects a scheduled meeting or initiates a new one.
If this is a scheduled session, it might already exist in the platform’s database with start time, host info, meeting ID, etc. If it’s an ad-hoc meeting, Alice’s client will create it on the fly.
Signaling Request
The client calls an endpoint like POST /signaling/join, providing minimal payload:
{
"meetingId": "<existing-or-new-meeting-id>",
"userId": "alice123",
"authToken": "Alice's-session-JWT-or-similar"
}
The Signaling Service authenticates Alice (using her authToken) and looks up the meeting’s status. If it’s a newly created meeting, the service also ensures a matching record in its ephemeral or central store to track active sessions.
SFU Details and ICE Servers
Once the meeting is recognized, the Signaling Service selects an appropriate SFU (Selective Forwarding Unit) region—e.g., “us-east” if Alice is in New York—and returns that SFU’s signaling URL, plus a list of ICE servers.
ICE servers typically include STUN and TURN addresses. This ensures that if Alice’s local network is restrictive (e.g., behind a corporate firewall), she can still connect via TURN relay.
Example
Suppose Alice’s client receives a response like:
{
"sfuUrl": "wss://sfu.useast.example.com",
"iceServers": [
{"urls": "stun:stun.global.example.com:3478"},
{"urls": "turn:turn.global.example.com:3478", "username": "x", "credential": "y"}
],
"sessionToken": "xyz123"
}
The client is now equipped to proceed with media negotiation.
Corner Cases
User Not Found or Unauthorized: If the auth token is invalid, the Signaling Service denies the request, returning an error. Alice cannot join.
Meeting Limit Exceeded: If the meeting has a max capacity (e.g., 100 participants) and is full, the Signaling Service returns a “Room Full” response, possibly offering to queue Alice or suggest a webinar format.
Invalid Region: If no SFU is available in the user’s locale (network outage in that region), the Signaling Service might fall back to a more distant data center, increasing latency but allowing the call to proceed.
2. Media Negotiation
SDP Exchange
Alice’s client begins by creating a local WebRTC session description (SDP Offer), describing the codecs (e.g., VP8/VP9/H.264 for video, Opus for audio) and network capabilities.
The client then sends this offer to the SFU via the Signaling Service (e.g., POST /signaling/offer) or a persistent WebSocket channel.
SFU Response
The SFU reads the offer and checks the available codecs or other parameters.
It replies with an SDP Answer, which the client applies locally. This answer details how the SFU expects to receive audio/video from Alice and how it will send media back to her.
STUN/TURN Procedures
As soon as the client knows the SFU’s ICE candidates, it attempts to establish a direct or relayed connection.
STUN servers help the client discover its public IP if behind NAT; TURN servers act as fallback relays if direct peer-to-server connections fail.
During this stage, Alice’s client might send multiple ICE candidates to the SFU. The SFU similarly shares any server reflexive or relayed candidates. Eventually, they discover at least one viable path (UDP port mapping, TCP fallback, or TURN relay over TLS).
Example
If Alice is on a home Wi-Fi with minimal NAT restrictions, the SFU typically finds a UDP path quickly, yielding good performance. If she suddenly moves to a corporate network with strict firewalls, the process might default to TURN over TCP, increasing latency a bit but preserving connectivity.
Corner Cases
Ice Gathering Timeout: If the client cannot gather a valid ICE candidate within a given time, the meeting join might fail, prompting a “Connection Failed” message.
Codec Mismatch: If the client only supports H.264 but the SFU insists on VP9, the call might not start, or the system must transcode. This is rare in well-managed environments, as most platforms define common sets of codecs.
Firewall Blocks WebSockets: Some corporate networks block WebSocket traffic. The client might have to fall back to secure polling or use an alternative HTTP-based signaling if supported.
3. Real-Time A/V
Media Flow
Once ICE negotiation finishes, Alice’s browser or native app starts capturing audio/video from her microphone/webcam.
The outgoing stream travels to the SFU, which then replicates it to other meeting participants.
Meanwhile, Alice receives inbound streams from the SFU representing each active speaker or participant.
Adaptive Bitrate (ABR)
The SFU or the client’s local WebRTC stack monitors network conditions—packet loss, jitter, round-trip time—and adjusts the send/receive bitrate.
If the SFU detects that Alice’s downlink is congested, it may lower the resolution from 720p to 480p, ensuring smoother playback rather than constant buffering or frame drops.
Logging & Monitoring
In the background, the SFU logs events such as “User alice123 joined,” “Current bitrate to Alice: 1.5 Mbps,” “Packet loss from Alice: 3%,” etc.
These logs are shipped to a Log Aggregator (e.g., Fluentd) and time-series metrics (bitrate, CPU usage) are stored in systems like Prometheus or InfluxDB.
Example
Suppose 10 participants are in the meeting. Each participant’s device uploads a single video stream (1–2 Mbps). The SFU receives ~10–20 Mbps total and sends each participant the combined streams (minus their own). If one participant temporarily experiences poor connectivity, the SFU might degrade that participant’s video feed to maintain audio quality.
Corner Cases
Mid-Call Mute/Unmute: If Alice mutes her microphone, the client signals the SFU that the outgoing audio track is disabled. The SFU no longer distributes audio for her.
Sudden Network Drop: If Alice’s connection drops, the SFU detects inactivity from her ICE session and logs a disconnection event. If she reconnects within a short window, her session can resume with minimal disruption.
Large Meeting: For a 100-person event, the SFU might only forward active speakers’ streams to each participant, or employ voice-activated switching to reduce overhead.
4. Recording On Demand
Host Trigger
If the host (or a designated co-host) decides to record, they call an endpoint like POST /recording/start. Typically, the meeting UI has a “Record” button.
This request might include details such as the desired recording format (individual tracks vs. a single mixed feed) or the layout mode (gallery view vs. active-speaker view).
Recording Service
If the platform uses an SFU-based system, the Recording Service can subscribe to each participant’s media track to create a local archive. Alternatively, if the platform employs an MCU for mixing, the Recording Service simply captures the already-mixed output.
The Recording Service also logs metadata about when recording started, which meeting ID it references, and who initiated the process.
MCU Approach for Large Meetings
In large webinars (e.g., 500+ attendees), an MCU often provides a single mixed feed for simplicity. The Recording Service just saves that single composite. This yields consistent playback later, but less flexibility for selective editing or dynamic layout changes.
Example
If the meeting is modest (5–10 people), the system might store individual audio/video tracks in parallel: Alice_track.webm, Bob_track.webm, etc. This enables advanced post-production, like focusing on the active speaker for highlight reels.
If it’s a huge corporate event, the system might generate a “grid view” or “spotlight speaker” feed in real time. Recording is limited to that single feed.
Corner Cases
Partial or Interrupted Recording: If the Recording Service crashes mid-session, partial segments are already saved. Upon restart, it might create a new file or attempt to resume. The final playback merges multiple segments.
Consent Requirements: Many jurisdictions require explicit notification to participants. The platform automatically pushes an in-meeting alert: “Recording in Progress. Your participation indicates consent.”
Resource Constraints: If the host tries to record but the server has insufficient CPU or storage, the system returns an error. Some platforms will gracefully queue the recording until a resource is freed.
5. Notification Workflow
Scheduled Reminders
If this meeting was scheduled in advance, the Notification Service might have already sent participants an email or push alert 15 minutes before start time—“Your meeting ‘Team Sync’ starts at 3 PM. Tap here to join.”
The service checks each participant’s notification preferences (email, mobile push, desktop notifications) and time zone offset to ensure timely delivery.
In-Meeting Alerts
The moment the host hits “Record,” participants receive an immediate banner or pop-up: “Recording started by Host.”
If the meeting has special constraints—e.g., “Meeting is locked”—the host can also push a notification to inform waiting participants they are on hold or not allowed to enter until unlocked.
Example
Suppose Bob missed the start time. Ten minutes into the meeting, the system might automatically send a push to Bob’s phone if he’s still offline—“Team Sync is in progress. Do you want to join now?”
During the call, if the system detects Bob’s network is failing, it might flash a local warning: “Your connection is unstable; consider turning off video.”
Corner Cases
Notification Overload: A user with multiple overlapping meetings may receive too many reminders. The platform can bundle them: “You have 3 upcoming meetings in the next 30 minutes.”
Expired Push Tokens: If the user’s mobile token expired, the push might fail. The system logs the error, possibly falling back to email or SMS.
Time Zone Confusion: If the meeting is at 3 PM ET, participants in Europe see a different local time. Ensuring the scheduler uses UTC behind the scenes is vital to avoid sending notifications at 3 PM local time in each region.
6. Meeting Ends
User Disconnect
After the meeting wraps up, participants begin leaving. Their clients send a disconnection signal to the SFU (e.g., “Bye” or simply ICE session termination).
The SFU notes each participant departure in its logs and final metrics—e.g., “alice123 left at timestamp 16:07:45.”
Finalize Recording
When the last participant or the host ends the meeting, the Recording Service automatically stops capturing. It closes the file streams and begins uploading the final media files to object storage (e.g., AWS S3).
The system saves metadata: meeting ID, start/end time, file size, possibly a recording title.
Post-Meeting Notifications
If the host or participants are interested in the recording, the Notification Service can push a “Recording is now available” email or push alert. This may include a direct playback link or instructions to visit the meeting history page.
In some cases, a summary notification is also sent, e.g., “10 people attended, average call quality was 4.2 out of 5.”
Example
Alice ends the call, prompting the client to call POST /meeting/end or close the WebRTC connection. The SFU sees no active participants remain. The Recording Service finalizes recording_12345.mp4 and places it in a designated S3 bucket.
A short while later, Alice receives an email: “Your meeting ‘Team Sync’ ended at 4:07 PM. The recording is available here.” She can click the link to watch or share it.
Corner Cases
Host Leaves Early: If the host leaves but the meeting is set to continue until all participants disconnect, the system must handle who “owns” the meeting afterward. Some platforms automatically transfer host privileges to another participant.
Force End: If an admin forcibly ends the meeting due to policy violations, the system abruptly disconnects all participants. The recording, if active, stops mid-stream.
Recording Finalization Failure: If object storage is temporarily down, the system might retry uploads until successful or store the final file locally with a background job reattempting.
7. Logs & Metrics
Detailed Ingestion
Throughout the entire session—from join to leave—each SFU node, signaling server, or recording process emits logs such as:
User events: “alice123 joined at 15:59:12,” “alice123 is speaking,” “alice123 left.”
System metrics: CPU usage, memory, bandwidth distribution, number of active streams.
Network quality data: Jitter, packet loss, round-trip time.
These logs flow into a log aggregation pipeline, often via tools like Fluentd or Logstash.
Real-Time Dashboards
The platform’s Monitoring Service might present an operational dashboard showing:
The total number of concurrent meetings system-wide.
The average packet loss per region.
The CPU load on each SFU node.
Operations staff can view these metrics in near real time to ensure the platform remains healthy.
Alerts and Post-Mortem
Automated triggers can fire if thresholds are exceeded—e.g., “SFU cluster CPU > 80% for 5 minutes.” The on-call engineer receives a PagerDuty alert to spin up new nodes or investigate.
If a participant complains about poor quality, an engineer can check logs correlating to that user’s session. They might discover that the participant’s packet loss spiked to 20% at 16:02, likely due to local Wi-Fi issues or a broader ISP outage.
Example
Suppose 100 participants joined a large meeting, causing a momentary surge in CPU usage on the SFU cluster. Log data pinned the spike at 15:59 as everyone joined simultaneously. The monitoring system triggered a scaling policy, adding two more SFU containers to handle the load. By 16:00, CPU usage was back below 60%, ensuring stable call quality.
Corner Cases
Log Overload: During massive global events, millions of lines of logs may flood the aggregator. If not scaled properly, logs could be dropped, hampering debugging efforts. A robust queue like Kafka helps buffer logs.
Sensitive Data: Some logs might inadvertently contain personal info. The platform must sanitize or hash user IDs, phone numbers, or email addresses to remain compliant with privacy regulations.
Inconsistent Timestamps: If different servers aren’t time-synchronized, the logs from one SFU might show a few seconds offset from another. Services like NTP mitigate these issues, aligning event timelines accurately.
