System Design Question 13- Design Youtube - Upload/Processing/Streaming/Discovery
From upload to streaming, search, recommendations, and analytics — a complete YouTube system design blueprint for scalable video platforms.

1. Understand the Problem as a User
We aim to design a YouTube-like video platform where users can upload videos, watch videos, search content, receive recommendations, and generate engagement signals such as likes, comments, subscriptions, and watch history.
Users interact with the system mainly through four flows:
Video Watching: Users open a video and expect low startup latency, adaptive quality, smooth playback, fast seek, and minimal buffering.
Video Uploading: Creators upload large raw videos, which are stored durably and processed asynchronously into multiple resolutions.
Search: Users search videos by intent, topic, creator, language, freshness, or popularity.
Recommendations: Users receive personalized home feed, related videos, “Up Next”, trending, and subscription-based suggestions.
The system also captures analytics events such as impressions, clicks, watch duration, pauses, likes, shares, skips, and subscriptions. These events improve ranking, recommendations, creator analytics, and system health.
Goal: Build a globally scalable, low-latency, highly available video streaming platform for millions of concurrent users.
2. Requirement Gathering
2.1 Functional Requirements
Video Upload
The system should support large video uploads, resumable uploads, upload progress tracking, retries, and upload session management.
Video Processing
The system should transcode raw videos into multiple resolutions such as 360p, 480p, 720p, 1080p, 1440p, and 2160p. It should also generate thumbnails, playback manifests, captions, and extracted metadata.
Video Streaming
The system should serve videos using adaptive bitrate streaming through CDN and edge locations.
Video Metadata
The system should store title, description, tags, creator, duration, thumbnail, visibility status, processing status, and moderation status.
Search
The system should support full-text search, typo tolerance, relevance ranking, freshness, popularity, filters, and creator/channel search.
Recommendations
The system should generate personalized home feed, related videos, “Up Next”, trending videos, and subscription-based recommendations.
Analytics
The system should capture impressions, clicks, watch duration, likes, skips, comments, shares, and subscriptions asynchronously.
Social Actions
The system should support likes, comments, subscriptions, playlists, and sharing at a high level.
2.2 Non-Functional Requirements
Scalability
The system should support hundreds of millions of daily active users, billions of video views per day, and millions of uploads per day.
Low Latency
Metadata APIs should respond within around 100 ms. Search should respond within around 200 ms. Recommendation APIs should respond within around 150 ms. Video startup time should generally be under 2 seconds.
High Availability
Watching should continue to work even if analytics, comments, or recommendations are degraded.
Durability
Uploaded raw videos and processed videos must not be lost.
Eventual Consistency
Search results, recommendations, view counts, like counts, and analytics dashboards can tolerate slight delay.
Global Delivery
The system should use CDN and edge delivery to serve video chunks close to users.
Adaptive Streaming
The system should support different resolutions and bitrates based on device type and network quality.
Observability
The system should track startup latency, buffering ratio, CDN cache hit ratio, processing lag, search latency, recommendation latency, and event ingestion lag.
2.3 Out of Scope
The following are out of scope for this design:
Live streaming, ads, creator monetization, copyright detection deep dive, payment systems, detailed ML training internals, and full comment moderation.
3. BOE Calculations / Capacity Estimation
Assume 500M DAU, each user watches 10 videos/day, does 3 searches/day, loads recommendations 5 times/day, and each video view generates around 20 analytics events. Also assume 5M uploads/day, average raw video size 500 MB, processed storage multiplier 3x, one day ≈ 100K seconds, and peak traffic ≈ 3x average.
This gives us:
Video views/day = 500M × 10 = 5B/day
Peak watch QPS = (5B / 100K) × 3 = ~150K QPS
Searches/day = 500M × 3 = 1.5B/day
Peak search QPS = (1.5B / 100K) × 3 = ~45K QPS
Recommendation requests/day = 500M × 5 = 2.5B/day
Peak recommendation QPS = (2.5B / 100K) × 3 = ~75K QPS
Uploads/day = 5M/day
Peak upload rate = (5M / 100K) × 3 = ~150 uploads/sec
Analytics events/day = 5B views × 20 events = 100B events/day
Peak event ingestion = (100B / 100K) × 3 = ~3M events/secFor storage and bandwidth:
Raw storage/day = 5M uploads × 500 MB = ~2.5 PB/day
Processed storage/day = 2.5 PB × 3 = ~7.5 PB/day
Total new video storage/day = ~10 PB/day
Assume avg watch time = 5 min and avg bitrate = 2 Mbps
Data/video = 2 Mbps × 300 sec = 600 Mb = ~75 MB
Daily streaming data = 5B views × 75 MB = ~375 PB/day
Peak streaming bandwidth ≈ ~90 TbpsBOE Summary
At 500M DAU, YouTube-like traffic becomes massive very quickly:
5B video views/day
150K peak watch QPS
45K peak search QPS
75K peak recommendation QPS
5M uploads/day
~10 PB new video storage/day
~375 PB streaming data/day
~90 Tbps peak streaming bandwidth
100B analytics events/day
~3M peak events/sec
Key Takeaways
YouTube is dominated by video streaming bandwidth, video storage, CDN delivery, metadata reads, search/recommendation QPS, and analytics ingestion.
The most important BOE insight is:
Watch traffic is huge.
Upload QPS is smaller, but upload size is massive.
Analytics ingestion is enormous.
CDN is mandatory.
Object storage is mandatory.
Async processing is mandatory.4. Approach “Think-Out-Loud” — High-Level Design
YouTube has two very different paths.
Upload path: write-heavy in file size, asynchronous, processing-intensive, but moderate QPS.
Watch path: extremely read-heavy, latency-sensitive, bandwidth-heavy, and globally distributed.
The first major design principle is:
API servers should not serve video bytes.
API servers serve metadata.
CDN/object storage serves video chunks.At a high level, the system must answer five questions:
I want to upload a video.
Use upload service, object storage, and asynchronous processing pipeline.
I want to watch a video.
Use streaming service, CDN, manifests, and adaptive video chunks.
I want to search videos.
Use search index, ranking, metadata cache, and filters.
I want recommendations.
Use candidate generation, ranking, feature store, and low-latency recommendation cache.
I want my activity captured.
Use asynchronous analytics event pipeline.
4.1 Why Not a Monolith?
A monolith is fine for an MVP, but at YouTube scale it fails because workloads are very different.
Upload handles large files and resumable upload sessions.
Transcoding is CPU/GPU-heavy and asynchronous.
Streaming is bandwidth-heavy and CDN-driven.
Metadata serving is high-QPS and low-latency.
Search needs full-text indexing and ranking.
Recommendations need user behavior, ML features, and fast serving.
Analytics is append-heavy and needs high-throughput event ingestion.
The justification is not “microservices are modern.” The justification is:
Different workloads need independent scaling, storage, latency targets, and failure isolation.5. Core Architecture
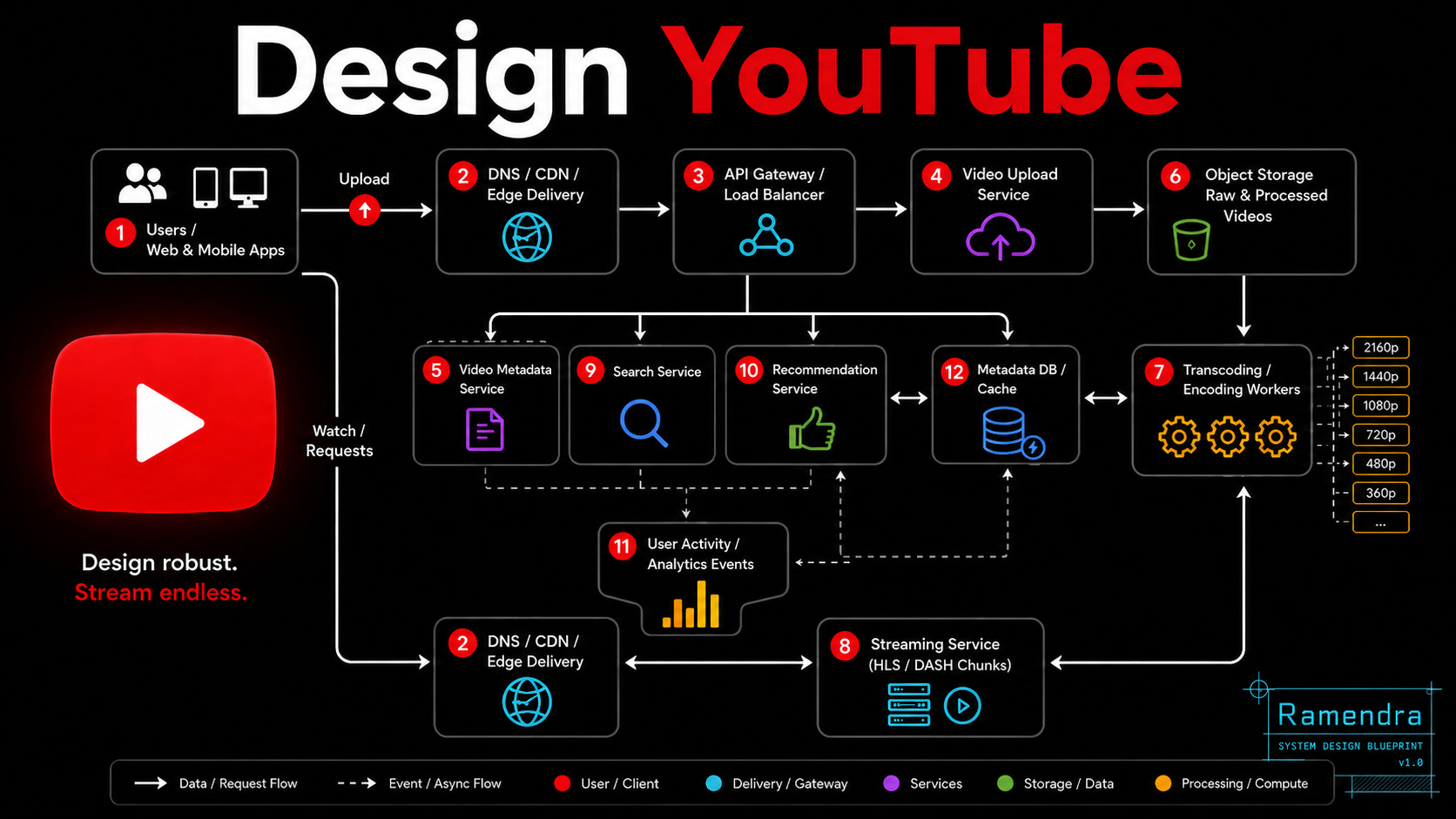
The architecture can be explained through five major flows.
5.1 Upload Flow
Users
→ DNS/CDN/Edge
→ API Gateway
→ Video Upload Service
→ Object Storage
→ Transcoding Workers
→ Processed Video Chunks
→ Streaming-ready StorageThe upload service should not directly process video. It should create an upload session, generate a pre-signed upload URL, store raw video in object storage, publish a video.uploaded event, and update video status as PROCESSING.
5.2 Processing Flow
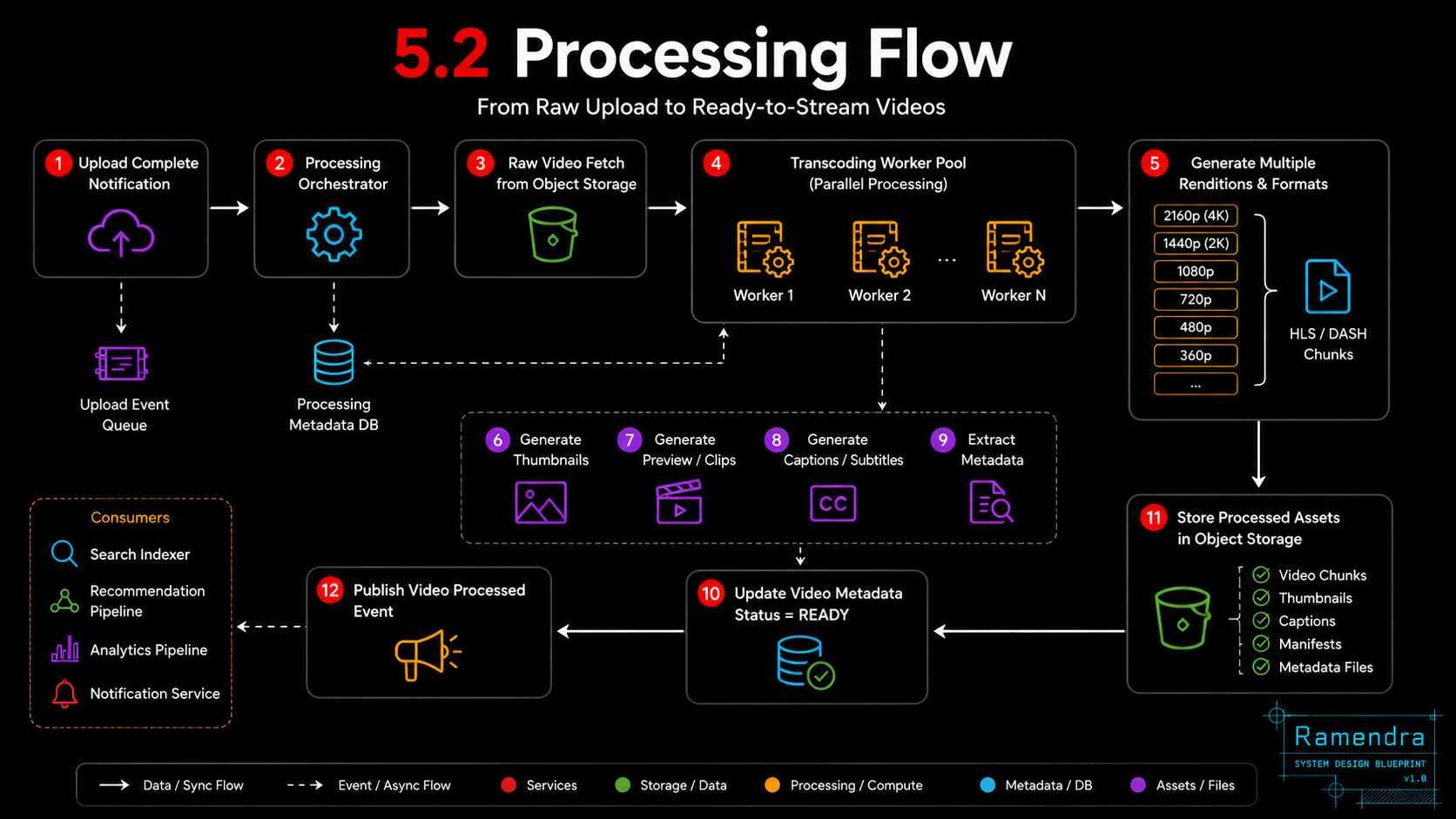
video.uploaded event
→ Transcoding Workers
→ Generate 360p/480p/720p/1080p/4K
→ Generate HLS/DASH chunks
→ Generate thumbnails
→ Store processed files
→ Update metadata status as READYProcessing is asynchronous because it can take seconds or minutes. The creator can see “Video is processing” while workers generate multiple formats.
5.3 Watch/Streaming Flow
User clicks video
→ API Gateway fetches metadata
→ Streaming Service returns playback manifest
→ Player requests chunks from CDN
→ CDN serves cached chunks
→ On cache miss, CDN fetches from origin/object storageThe important point:
The app server returns metadata and manifest.
The video chunks come from CDN.This protects backend services from huge bandwidth load.
5.4 Search / Recommendation Flow
User request
→ API Gateway
→ Search Service / Recommendation Service
→ Metadata Cache
→ Video cards returnedSearch and recommendation return video cards, not video bytes.
A video card contains:
videoId, title, thumbnailUrl, duration, creator, viewCount, freshness, rankScore5.5 Discovery Flow
User opens Search / Home Feed
→ API Gateway
→ Search Service / Recommendation Service
→ Search Index / Feature Store
→ Ranking Layer
→ Metadata Cache
→ Home Feed / Search Results / Related Videos 6. Service Responsibilities
API Gateway
Handles authentication, routing, rate limiting, TLS termination, and request validation.
Video Upload Service
Handles upload session creation, resumable upload, raw video validation, and upload status tracking.
Object Storage
Stores raw videos, processed videos, thumbnails, manifests, and captions.
Transcoding Workers
Convert raw videos into multiple resolutions and streaming chunks.
Video Metadata Service
Stores title, description, creator, tags, visibility, duration, moderation state, and processing status.
Streaming Service
Returns playback manifest, validates playback access, and coordinates chunk delivery.
Search Service
Indexes videos and returns ranked search results.
Recommendation Service
Serves home feed, related videos, and “Up Next” recommendations.
Analytics/Event Service
Captures user behavior and feeds downstream pipelines.
Metadata DB/Cache
Serves high-QPS metadata reads with low latency.
7. Databases & Rationale
Raw and Processed Videos → Object Storage
Object storage is used because videos are large blobs. It provides durability, scalability, replication, and lower cost than storing videos in databases.
Video Metadata → NoSQL / Wide-Column Database
Video metadata needs high read/write scale and flexible fields. Partitioning can be done by videoId, creatorId, or upload time depending on access pattern.
Metadata Cache → Redis / Memcached
Hot video metadata should be cached because watch pages are extremely read-heavy.
Search → Search Index
A search-optimized index is needed for full-text search, ranking, filtering, typo tolerance, and freshness scoring.
Recommendations → Key-Value Store + Feature Store
Recommendation serving needs fast lookup such as userId → recommendedVideos and videoId → relatedVideos.
Events → Distributed Event Streaming Platform
Analytics events are high-volume, append-only, and need asynchronous processing.
Analytics → Data Lake / Warehouse
Long-term analytics, creator dashboards, ML training, and business intelligence need a data lake or warehouse.
Counters → Distributed Counter Store
Views, likes, comments, and shares need scalable counters. These can be eventually consistent.
8. Key APIs
We need only a small set of APIs for the main YouTube flows: upload, watch, search, recommendations, events, and basic engagement.
POST /videos/upload-sessionCreates an upload session and returns upload URLs for resumable/chunked upload.
PUT /videos/upload/{sessionId}/chunkUploads one video chunk. Supports retry using sessionId and chunkId.
POST /videos/{videoId}/completeMarks upload as complete and triggers async video processing.
GET /videos/{videoId}Fetches video metadata: title, description, creator, thumbnail, duration, visibility, and processing status.
GET /videos/{videoId}/manifestReturns playback manifest with available resolutions and HLS/DASH chunk information.
GET /search?q={query}&filters={filters}Returns ranked video cards for search results.
GET /recommendations/home?userId={userId}Returns personalized home feed videos.
GET /recommendations/videos/{videoId}Returns related videos for the watch page.
POST /eventsCaptures user activity such as impression, click, watch duration, pause, skip, like, share, and subscribe.
POST /videos/{videoId}/like
POST /channels/{channelId}/subscribeHandles basic engagement actions.
API Design Notes
APIs should be idempotent where needed, especially upload chunk, complete upload, like, and subscribe.
Search and recommendation APIs should support pagination/cursor-based loading, because feeds and search results are infinite-scroll style.
Video APIs should return metadata and manifest only. Actual video chunks should be served by CDN/object storage, not by application servers.
9. Core Tradeoffs So Far
CDN for video chunks
Benefit: low latency, reduced origin load, better global delivery.
Tradeoff: CDN cost and cache invalidation complexity.
Async transcoding
Benefit: better upload experience and scalable processing.
Tradeoff: video is not instantly available in all resolutions.
Object storage
Benefit: durable, cheap, scalable blob storage.
Tradeoff: higher latency than local storage.
Search index
Benefit: fast retrieval and ranking.
Tradeoff: eventual consistency with metadata updates.
Metadata cache
Benefit: low-latency watch page reads.
Tradeoff: stale metadata is possible.
Recommendation cache
Benefit: fast feed serving.
Tradeoff: personalization can lag.
Async analytics
Benefit: user-facing APIs stay fast.
Tradeoff: analytics and ranking updates are delayed.
10. Data Model
At YouTube scale, we should not keep everything in one relational schema. The data model is service-aligned.
Video Metadata
Video {
videoId
creatorId
channelId
title
description
tags[]
category
language
duration
thumbnailUrl
visibilityStatus
processingStatus
moderationStatus
createdAt
updatedAt
}This is the canonical metadata used by watch page, search, recommendation, channel pages, and playlists.
Video Asset
VideoAsset {
videoId
rawVideoPath
processedRenditions[]
manifestUrl
thumbnailUrls[]
captionUrls[]
storageRegion
createdAt
}This separates metadata from large video files. Metadata lives in DB/cache. Video bytes live in object storage/CDN.
Processed Rendition
Rendition {
videoId
resolution
bitrate
codec
chunkPath
manifestPath
status
}Each uploaded video produces many renditions such as 360p, 720p, 1080p, and 4K.
User Activity Event
UserActivityEvent {
eventId
userId
videoId
eventType
sessionId
watchPosition
device
country
timestamp
}Events include impression, click, video_start, pause, resume, watch_progress, like, share, skip, and subscribe.
Recommendation Cache
UserRecommendations {
userId
recommendedVideoIds[]
generatedAt
ttl
}Recommendation serving should be fast. The online path should not compute everything from scratch.
11. Indexes
Metadata DB Indexes
Use videoId as the primary lookup key.
Additional indexes:
creatorId + createdAt
channelId + createdAt
visibilityStatus + createdAt
processingStatus
category + createdAtThese help with creator studio, channel pages, moderation queues, and recently uploaded videos.
Search Index Fields
Search index should store denormalized searchable fields:
videoId
title
description
tags
creatorName
channelName
category
language
thumbnailUrl
duration
viewCount
likeCount
freshnessScore
popularityScoreSearch should not call multiple services at query time. It should return ranked video cards from a denormalized index.
Recommendation Indexes
Common access patterns:
userId → recommendedVideoIds
videoId → relatedVideoIds
channelId → recentPopularVideos
country/language → trendingVideos12. Detailed Request Flows
12.1 Video Upload Flow
1. Client requests upload session.
2. API Gateway routes request to Video Upload Service.
3. Upload Service creates videoId and upload session.
4. Upload Service returns pre-signed upload URLs.
5. Client uploads chunks directly to object storage.
6. Client marks upload complete.
7. Upload Service validates uploaded chunks.
8. Upload Service stores metadata with PROCESSING status.
9. Upload Service publishes video.uploaded event.
10. Transcoding workers consume the event asynchronously.Key design decision:
The raw video should go directly to object storage.
Application servers should coordinate upload, not carry video bytes.This improves scalability and protects API servers from large file bandwidth.
12.2 Transcoding Flow
1. Transcoding worker consumes video.uploaded event.
2. Worker fetches raw video from object storage.
3. Worker generates multiple resolutions and bitrates.
4. Worker creates HLS/DASH chunks.
5. Worker generates thumbnails and preview assets.
6. Worker stores processed assets in object storage.
7. Worker updates Video Metadata Service with READY status.
8. Worker publishes video.processed event.
9. Search and recommendation pipelines consume the update.Transcoding is async because it is CPU/GPU-heavy and can take time. The creator can see “processing” until the video is ready.
12.3 Watch Flow
1. User opens video.
2. Client calls GET /videos/{videoId}.
3. API Gateway routes to Video Metadata Service.
4. Metadata Service checks cache.
5. On cache miss, metadata is fetched from metadata DB.
6. Client calls GET /videos/{videoId}/manifest.
7. Streaming Service validates video availability and access.
8. Streaming Service returns HLS/DASH manifest.
9. Player requests video chunks from CDN.
10. CDN serves cached chunks.
11. On CDN miss, CDN fetches chunks from object storage/origin.
12. Client emits watch events asynchronously.Most important point:
Metadata comes from application services.
Video chunks come from CDN.This is the difference between a scalable video platform and a backend that collapses under bandwidth load.
12.4 Search Flow
1. User sends search query.
2. API Gateway routes to Search Service.
3. Search Service normalizes query.
4. Search Service queries search index.
5. Ranking layer applies relevance, freshness, popularity, and personalization signals.
6. Search Service returns video cards.
7. Client emits impression and click events.Search should return lightweight video cards:
videoId, title, thumbnailUrl, creatorName, duration, viewCount, rankScoreSearch should not fetch large video files or call many services synchronously.
12.5 Recommendation Flow
1. User opens home feed or watch page.
2. Client calls Recommendation Service.
3. Recommendation Service checks precomputed candidate cache.
4. Ranking layer reorders candidates using user context.
5. Service fetches hot metadata from cache.
6. Feed returns ranked video cards.
7. User actions generate analytics events.
8. Events feed offline and near-real-time recommendation pipelines.Recommendation has two layers:
Candidate generation: find possible videos.
Ranking: order videos for this user/context.For fallback, show trending videos, subscribed-channel videos, or popular videos in the user’s language/region.
13. Scaling Strategy
CDN Scaling
CDN is the most important scaling layer for playback.
Use CDN for:
video chunks
thumbnails
captions
preview clips
static player assetsPopular videos should be cached aggressively at edge locations. Long-tail videos may be fetched from origin on demand.
Metadata Scaling
Metadata reads are high-QPS. Use:
read replicas
distributed cache
partitioning by videoId
hot-key protection
short TTL for frequently changing counters
longer TTL for stable fieldsSeparate stable metadata from volatile counters. Title and duration rarely change. View count and like count change frequently.
Upload Scaling
Uploads should scale through:
pre-signed URLs
multipart upload
direct-to-object-storage upload
upload session state
chunk retry
background validationAPI servers should not become file transfer servers.
Transcoding Scaling
Transcoding workers should scale horizontally.
Use separate queues for:
standard videos
large videos
4K videos
priority creators
retry jobs
failed jobsThis prevents one heavy job type from blocking everything else.
Search Scaling
Search index should be sharded and replicated.
Use:
shards for scale
replicas for availability
denormalized documents
async indexing from metadata events
query result caching for hot searchesSearch can be eventually consistent. A newly uploaded video may take some time to appear.
Recommendation Scaling
Use precomputation plus online ranking.
Offline jobs generate candidates.
Online service ranks and personalizes.
Cache stores user feeds and related videos.
Fallback serves trending/popular videos.Do not compute the entire recommendation feed synchronously on every request.
14. Consistency Model
YouTube can use mixed consistency.
Stronger Consistency Needed
Use stronger consistency for:
video ownership
visibility/privacy status
delete/takedown status
upload completion state
access controlIf a creator deletes a video or makes it private, the system should enforce it quickly.
Eventual Consistency Acceptable
Eventual consistency is acceptable for:
view count
like count
comment count
search indexing
recommendation updates
analytics dashboards
creator analytics
trending scoreA view count being delayed by a few seconds is acceptable. A private video being publicly visible is not acceptable.
15. Failure Handling
CDN Failure
If one edge location fails:
route to another edge
fallback to regional CDN
fallback to origin only as last resortObject Storage Failure
Use:
multi-zone replication
cross-region replication for critical assets
retry with exponential backoff
origin failoverTranscoding Failure
Use:
retry queue
dead-letter queue
job checkpointing
partial output cleanup
manual reprocessing optionIf 4K processing fails but 720p is ready, the video can still be made available at lower quality.
Metadata Cache Failure
Fallback to metadata DB, but protect DB using:
rate limiting
request coalescing
circuit breakers
stale cache servingRecommendation Failure
Fallback options:
trending videos
subscribed-channel videos
popular videos by region/language
cached previous feedVideo watching should continue even if recommendations fail.
Analytics Failure
Buffer events locally or at the collector.
drop non-critical events under extreme load
prioritize watch_start and watch_duration
never block playback due to analytics failure16. Observability
Track product metrics and infrastructure metrics together.
Playback Metrics
video startup time
buffering ratio
rebuffer count
average bitrate
playback failure rate
CDN cache hit ratio
chunk fetch latencyUpload/Processing Metrics
upload success rate
upload retry rate
processing queue lag
transcoding duration
transcoding failure rate
videos stuck in PROCESSINGSearch/Recommendation Metrics
search latency
zero-result rate
click-through rate
watch time from search
recommendation CTR
recommendation watch time
feed refresh latencySystem Metrics
API latency
error rate
cache hit ratio
DB QPS
event ingestion lag
consumer lag
queue depth
regional availabilityFor YouTube-like systems, watch-time quality is as important as backend uptime.
17. Security and Abuse Protection
Upload Security
Validate file type, scan for malware, enforce file size limits, and prevent abuse through upload rate limits.
Access Control
Respect visibility states:
public
private
unlisted
members-only
age-restricted
region-restrictedStreaming Service must validate access before returning playback manifests.
API Protection
Use:
authentication
rate limiting
bot detection
abuse detection
signed URLs
short-lived playback tokensContent Safety
At high level, use automated and manual moderation pipelines for:
copyright violations
harmful content
spam
misleading metadata
fake engagementThis can be a separate deep-dive system.
18. Evolution Plan
MVP
Start simple:
single region
basic upload
object storage
basic transcoding
basic metadata DB
basic playback
simple search
simple trending feedThis is enough for a small video platform.
V1 Production
Add:
CDN delivery
resumable uploads
async transcoding pipeline
metadata cache
search index
event streaming
basic recommendation service
monitoring and alertsThis supports real user growth.
Planet Scale
Add:
multi-region architecture
global CDN strategy
advanced adaptive bitrate streaming
large-scale search ranking
ML-based recommendations
feature store
real-time analytics
hot-key protection
multi-region failover
abuse and safety pipelinesAt planet scale, YouTube becomes a combination of distributed storage, CDN delivery, stream processing, search ranking, recommendation systems, and massive observability.
19. Final Design Summary
The key design is to separate the system into specialized paths:
Upload path:
Client → Upload Service → Object Storage → Transcoding Workers
Watch path:
Client → Metadata/Manifest APIs → CDN → Video Chunks
Search path:
Client → Search Service → Search Index → Video Cards
Recommendation path:
Client → Recommendation Service → Candidate Cache → Ranking → Video Cards
Analytics path:
Client Events → Event Stream → Analytics / ML / Ranking PipelinesThe most important architectural decisions are:
Do not serve video bytes from API servers.
Use object storage for raw and processed videos.
Use CDN for global video delivery.
Use async workers for transcoding.
Use cache for hot metadata.
Use search index for video discovery.
Use precomputed recommendation candidates.
Use event streaming for analytics.
Accept eventual consistency where user experience allows it.
Enforce stronger consistency for privacy, deletion, and access control.That is the core architecture of a YouTube-like system.